


Solving the Object Identity Problem
TL;DR - matching entities in different structured and unstructured datasets drives value

Welcome to the 16 new subscribers who have joined us since our last post! If you haven’t subscribed, join 268 smart, curious members of the Data & Analytics community by subscribing here:
Please do consider sharing this newsletter with friends or colleagues who you think may be interested. Thank you!
If you want to build a large dataset of information, one problem you inevitably face is the difficulty of combining different sources that don’t share a unique identifier.
Whether your data is about companies, people, or something else, if you are pulling together information from different sources (public and/or proprietary) at some point you will run into this issue.
Matching datasets is a huge problem for every organisation. Use cases include:
Creating and managing marketing databases;
Mapping customer behaviours across different products;
Mapping user traffic across the web;
Identifying bad actors IRL or online.
The process of combining these data sources goes by many different names. This extract from the Wikipedia page on “Record Linkage” gives you an idea of the number of different terms involved:
Record linkage (also known as data matching, data linkage, entity resolution, and many other terms) is the task of finding records in a data set that refer to the same entity across different data sources (e.g., data files, books, websites, and databases). Record linkage is necessary when joining different data sets based on entities that may or may not share a common identifier (e.g. database key, URI).
Computer scientists often refer to it as "data matching" or as the "object identity problem". Commercial mail and database applications refer to it as "merge/purge processing" or "list washing". Other names used to describe the same concept include: "coreference/entity/identity/name/record resolution", "entity disambiguation/linking", "fuzzy matching", "duplicate detection", "deduplication", "record matching", "(reference) reconciliation", "object identification", "data/information integration" and "conflation".
I’ve been involved with numerous projects in the past focused on creating very large, clean databases from a variety of data sources.
What I’ve observed is that it is very difficult to get to high levels of accuracy without human intervention. Without going into lots of detail here, there’s always some level of ambiguity which software cannot resolve.
Unsurprisingly, a significant problem like this attracts a range of providers attempting to provide a solution.
Master Data Management providers have been trying to crack this for many years. Here’s the Gartner Magic Quadrant for MDM from 2021:
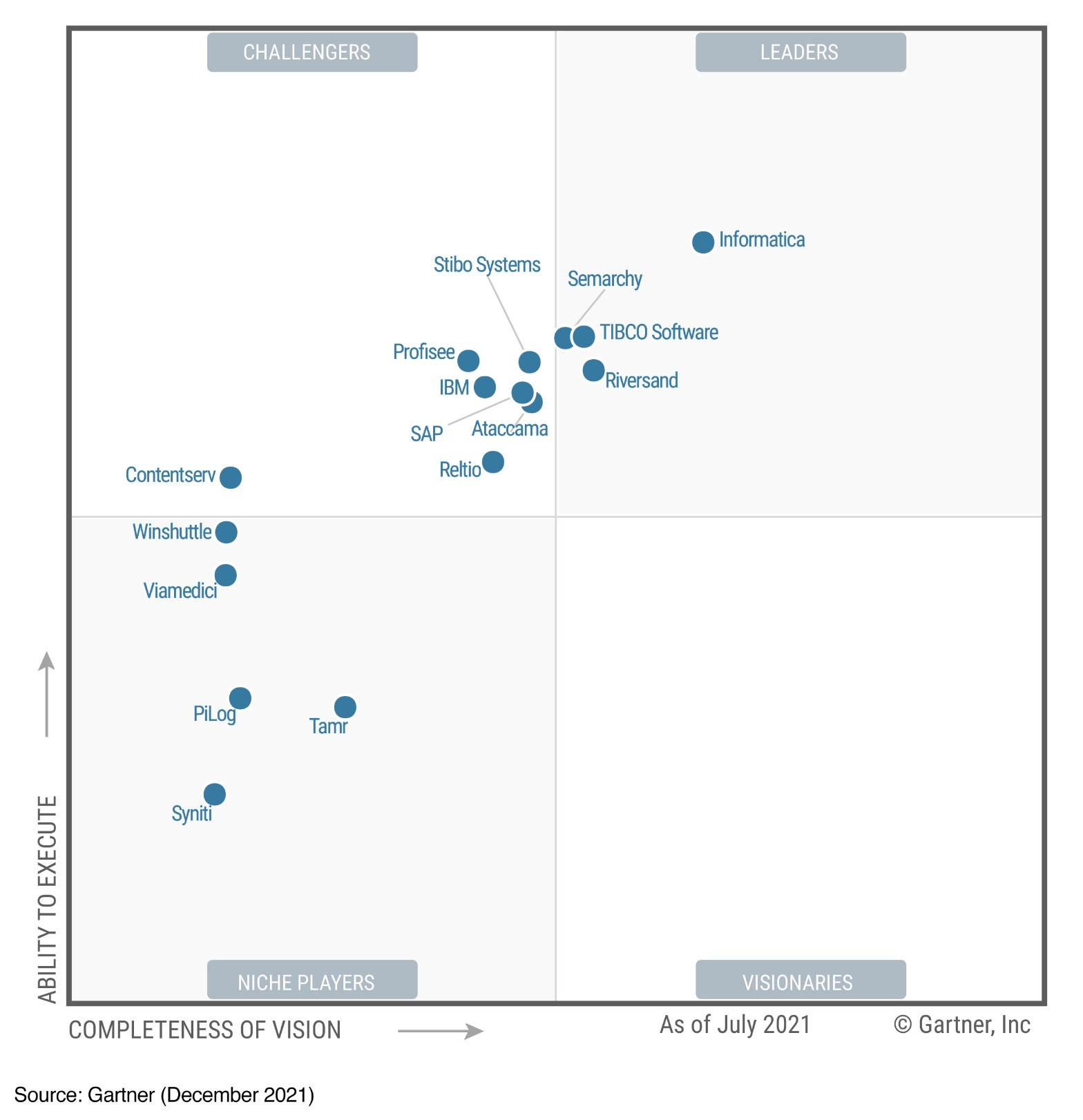
There are some big names on there including IBM, SAP, TIBCO and Informatica.
And yet the problem still exists. And across multiple extremely large sectors (e.g. Marketing, Advertising, Financial Services).
So new entrants to the market continue to arise, claiming improved accuracy and products and services tailored to specific end-markets.
The following Entity Resolution providers have particularly caught my eye:

Backers include GIC, Warburg Pincus, HSBC, Dawn Capital, Evolution Equity Partners, AlbionVC and British Patient Capital;
Claims 99% data matching accuracy;
Main focus is on anti-fraud/AML, but the underlying data matching engine can be used for anything;
Partnership with Dun & Bradstreet “fusing best-in-class data matching and graph analytics capabilities from Quantexa’s Decision Intelligence Platform with Dun & Bradstreet’s rich data insights.”
Backed by Wood Mackenzie owners Veritas Capital and Dorilton;
Originally a Text Analytics company, pivoting into Entity Resolution through acquisition:
Key technology is the Rosette Match Identity fuzzy matching product, (Rosette acquired by Babel Street in November 2022);
Mainly focused on (person) name matching within publicly available information;
Particular focus on government-related threats including Border Security, OSINT and criminal behaviour;
Acquired Vertical Knowledge, aggregator of publicly available datasets in January this year.
Founded by Entity Resolution veteran, Jeff Jonas;
Backed by Peter Thiel’s Mithril Capital;
Sell into IBM - who have their own MDM software - always a good sign!
For the majority of Data & Analytics companies, stitching together datasets is of critical importance. In the last few weeks I have profiled HG Insights, S&P Global, Revelio Labs, AlphaSense and Tegus. All of these companies are in the business of creating joined-up datasets. As I mentioned last week, the more data you can join together, the more powerful your solution becomes.
And investors can benefit from this too, as they transition to being more data driven. We covered this topic a few weeks ago when we looked at EQT and their Motherbrain platform.
The Senzing blog has a lot of great collateral explaining why (unsurprisingly, given that it’s marketing material from an Entity Resolution provider) it makes sense to buy this technology in rather than build it yourself.
Ultimately, the answer to whether to buy or build this capability lies in your priorities, resourcing and focus.
However, I expect to see more companies using third-party SaaS providers as AI specialisation evolves and it becomes harder for companies to build state-of-the-art Entity Resolution in house.
Here are a few other things I’ve enjoyed reading this week:
A research paper commissioned by S&P Global on Deal Sourcing: A Data Science Approach: Impact of Financial Characteristics on Acquisition Likelihood. Thank you to Massimo Bellino, founder of M&A Compass, for the share;
Interesting podcast from S&P’s Private Markets 360 on Private Equity firm portfolio company value creation;
I’m running a few bookclubs this year as a way to push me to read and finish more books. I’ve started two more clubs in the past month - one for Mindfulness and one for Japanese Literature in Translation. See the list of clubs and books below. If you would like to join me in reading any of these, please drop me a line. The rules for all the clubs are the same:
One book every two months;
Choice rotates between bookclub members.
On the subject of Japanese literature, I can’t recommend Alison Fincher’s Read Japanese Literature podcast highly enough - I recently signed up as a Patreon supporter.
Love it! We struggled with this a lot at CircleUp, where we were working on building a giant database of every CPG company in the US, from lots of different data sources. It was very challenging. It does seem like something that LLMs could help a lot with, but I haven't worked on this type of problems since they've become available